Gemini 3.1 Flash-Lite is Google’s latest generative AI model. It is designed to deliver fast responses and lower costs for developers and enterprises running artificial intelligence workloads at scale.
Meanwhile, the release expands the Gemini large language model (LLM) family. It also reflects Alphabet’s broader push to strengthen its position in the rapidly evolving generative AI market. Competitors including OpenAI, Anthropic, Meta, and Microsoft are also racing to deliver faster and more efficient AI systems.
Gemini 3.1 Flash-Lite AI Model Designed for High-Volume Inference
According to Google, Gemini 3.1 Flash-Lite was built for applications that process large numbers of AI requests. The goal is to maintain low latency and predictable infrastructure costs.
Today, these workloads are becoming increasingly common. Companies are deploying generative AI features across customer support tools, productivity software, analytics platforms, and enterprise automation systems.
The model is available through the Gemini API, Google AI Studio, and Vertex AI on Google Cloud. As a result, developers can integrate it into chat interfaces, automation tools, and enterprise applications.
Google said the model delivers faster response times than earlier Flash models. In addition, it maintains strong capabilities in natural language understanding, reasoning, and coding assistance.
Key Features of the Gemini 3.1 Flash-Lite AI Model
The model supports production-grade AI deployments. In these environments, performance and efficiency are critical.
- Optimized for high-volume AI inference workloads
- Lower operational costs for enterprise AI deployments
- Support for translation, summarization, and automated workflows
- Integration with Google Cloud infrastructure and Vertex AI
- Adjustable reasoning settings to balance speed and model intelligence
Developers can tune reasoning levels depending on task complexity. As a result, applications can balance computational cost and performance when generating responses.
Pricing Designed for Scalable AI Infrastructure
Cost efficiency is one of the primary advantages of the model. According to Google, the pricing targets organizations processing millions of AI queries each day.
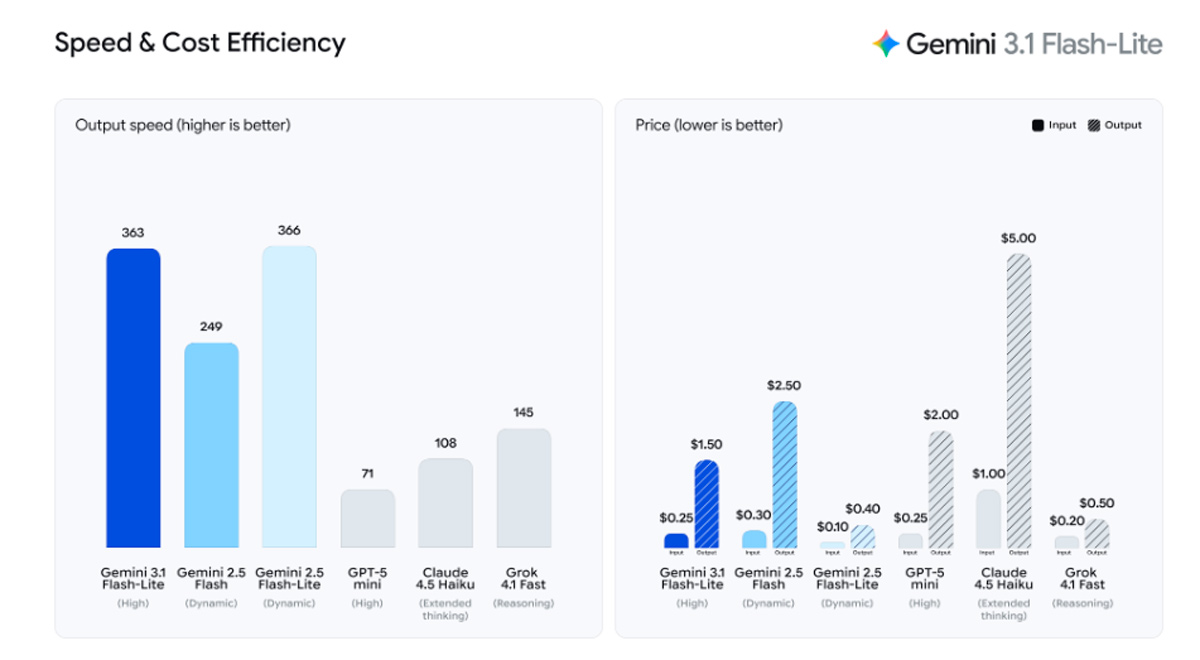
The model is priced at roughly $0.25 per million input tokens and $1.50 per million output tokens. This places it among the more affordable AI systems designed for large-scale inference workloads.
Meanwhile, analysts say the generative AI sector is shifting toward efficient inference. Companies are focusing less on larger foundation models and more on scalable infrastructure.
“The AI race is increasingly shifting toward cost-efficient inference and scalable infrastructure,” analysts said. “Organizations deploying generative AI in production need models that can handle massive workloads without dramatically increasing compute costs.”
Google Expands the Gemini AI Ecosystem
The introduction of Gemini 3.1 Flash-Lite is part of Google’s broader strategy. The company continues expanding the Gemini AI platform with models optimized for different performance and cost requirements.
Google is integrating Gemini across its ecosystem, including Google Cloud, Workspace, Search, Android, and developer platforms. As a result, Gemini is becoming a core component of the company’s AI infrastructure strategy.
Meanwhile, specialized models such as Flash-Lite are designed to power everyday AI applications. These include chatbots, productivity tools, and enterprise automation software.
Efficiency Becomes a New Battleground in the AI Model Market
However, the launch highlights a broader shift in the generative AI industry. Early competition focused on building the most powerful large language models.
Today, technology companies are investing heavily in efficient AI systems. These models are optimized for speed, scalability, and lower inference costs.
Companies including Google, OpenAI, Anthropic, and Meta are rapidly developing lightweight AI models capable of serving millions of user requests per day.
For Google, expanding the Gemini model lineup could strengthen adoption of Google Cloud AI infrastructure.
Meanwhile, readers interested in broader developments across artificial intelligence can explore the latest AI news and industry updates covering new models, startups, and AI technology trends.
As a result, efficient models like Gemini 3.1 Flash-Lite are likely to play an increasingly important role in the global AI infrastructure ecosystem.



