По состоянию на март 2026 года отсутствуют официальные анонсы, бенчмарки или техническая документация по следующей ИИ-модели DeepSeek, что означает неподтверждённость её спецификаций. Опираясь на тренды масштабирования, наблюдавшиеся в DeepSeek-V2, а также на сопоставимые frontier-системы с архитектурой mixture-of-experts, предполагаемую производительность можно оценить через эффективность разреженного масштабирования и ориентиры класса MLCommons по инференсу. Данный материал является техническим прогнозом, а все показатели производительности и инфраструктуры представлены как инженерные оценки (~Value est.).
- Прогнозируемое общее число параметров: ~1,0–1,3 трлн (оценка), официальные бенчмарки на данный момент отсутствуют
- Прогнозируемая пропускная способность инференса: ~350–500 токенов/сек на узел класса NVIDIA H100 (оценка), в зависимости от доли активируемых экспертов
- Прогнозируемый бюджет вычислений на обучение: >5e25 FLOPs суммарно (оценка), в соответствии с законами масштабирования разреженных моделей триллионного класса
Операционные параметры
- Энергетическая нагрузка: обучение и эксплуатация разреженной модели с триллионом параметров, по прогнозу, потребуют устойчивой плотности энергопотребления на уровне ~80–120 кВт на стойку (оценка), что стимулирует внедрение жидкостного охлаждения «чип-к-чипу» и высокоэффективных систем электропитания.
- Вычислительная плотность: архитектура sparse mixture-of-experts позволяет активировать лишь ~5–10% общего числа параметров на один токен, обеспечивая рост эффективного масштаба модели без пропорционального увеличения вычислений и более высокую производительность на ватт по сравнению с плотными архитектурами.
- Стратегические сроки: темпы внедрения будут в значительной степени зависеть от доступности ускорителей, поставок высокоскоростных межсоединений и зрелости кластерной интеграции; ориентировочный цикл развёртывания — 6–12 месяцев после завершения первичного обучения модели.
Архитектура маршрутизации
Предполагаемая система, вероятно, развивает иерархическую маршрутизацию mixture-of-experts, объединяя разреженные экспертные feedforward-слои с общей «спинкой» механизма внимания. Токены динамически направляются к ограниченному числу экспертов, что снижает объём активных вычислений при сохранении общего масштаба параметров. Производительность критически зависит от пропускной способности межсоединений, балансировки нагрузки между экспертами и эффективности доступа к памяти в распределённых GPU-кластерах.
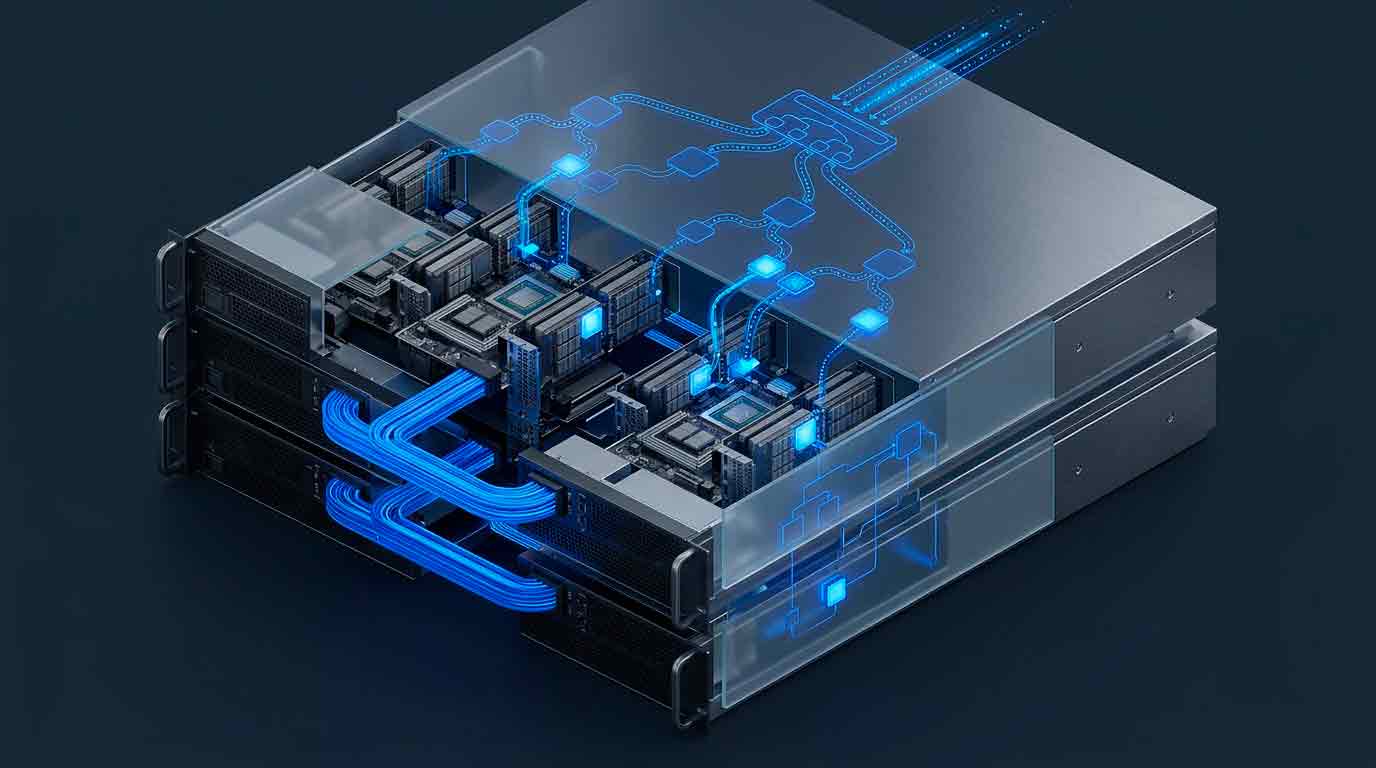
Профиль производительности
Разреженные модели триллионного класса смещают ключевые ограничения производительности с чистой вычислительной мощности на пропускную способность памяти и эффективность межсоединений. По сравнению с плотными моделями, такие системы обеспечивают более высокую пропускную способность на единицу вычислений, но требуют более сложной оркестрации и планирования. Этот архитектурный сдвиг напрямую влияет на проектирование дата-центров, экономику инференса и стратегии загрузки ускорителей.
| Модель | Архитектура | Активные параметры на токен | Статус |
|---|---|---|---|
| DeepSeek (прогноз) | Разреженная MoE | ~50–100 млрд (оценка) | Прогноз |
| DeepSeek-V2 | Разреженная MoE | ~20–40 млрд | Выпущена |
| Класс GPT-4 | Плотная / гибридная (не раскрыто) | Не раскрыто | Выпущена |
| Gemini 1.5 Pro | Разреженная / гибридная | Не раскрыто | Выпущена |
С точки зрения CTO, разреженные архитектуры триллионного класса смещают узкое место масштабирования от вычислительной мощности к пропускной способности межсоединений, эффективности памяти и устойчивости распределённых систем.
Аналитика Ainformer
Прогнозируемая следующая модель DeepSeek соответствует отраслевому переходу к разреженному масштабированию как доминирующему способу наращивания возможностей frontier-ИИ. Вместо линейного увеличения вычислений с ростом размера модели разреженная маршрутизация позволяет экспоненциально расширять число параметров при сохранении приемлемых эксплуатационных затрат и задержек инференса.
При успешном развёртывании такая система способна усилить региональную технологическую автономию в сфере ИИ и ускорить внедрение крупномасштабных автономных систем. Критическим ограничивающим фактором станет не столько дизайн модели, сколько доступность высокоскоростных ускорителей, эффективных кластерных сетей и инфраструктуры электропитания и охлаждения дата-центров, обеспечивающих непрерывную работу.



