OpenAI GPT-5.4 Mini and Nano have been introduced as smaller AI models designed for lightweight use cases, with availability through Microsoft’s Azure AI Foundry platform. According to the companies, the release focuses on lower-latency responses, cost efficiency, and deployment flexibility across the AI news landscape.
What happened with GPT-5.4 Mini and Nano
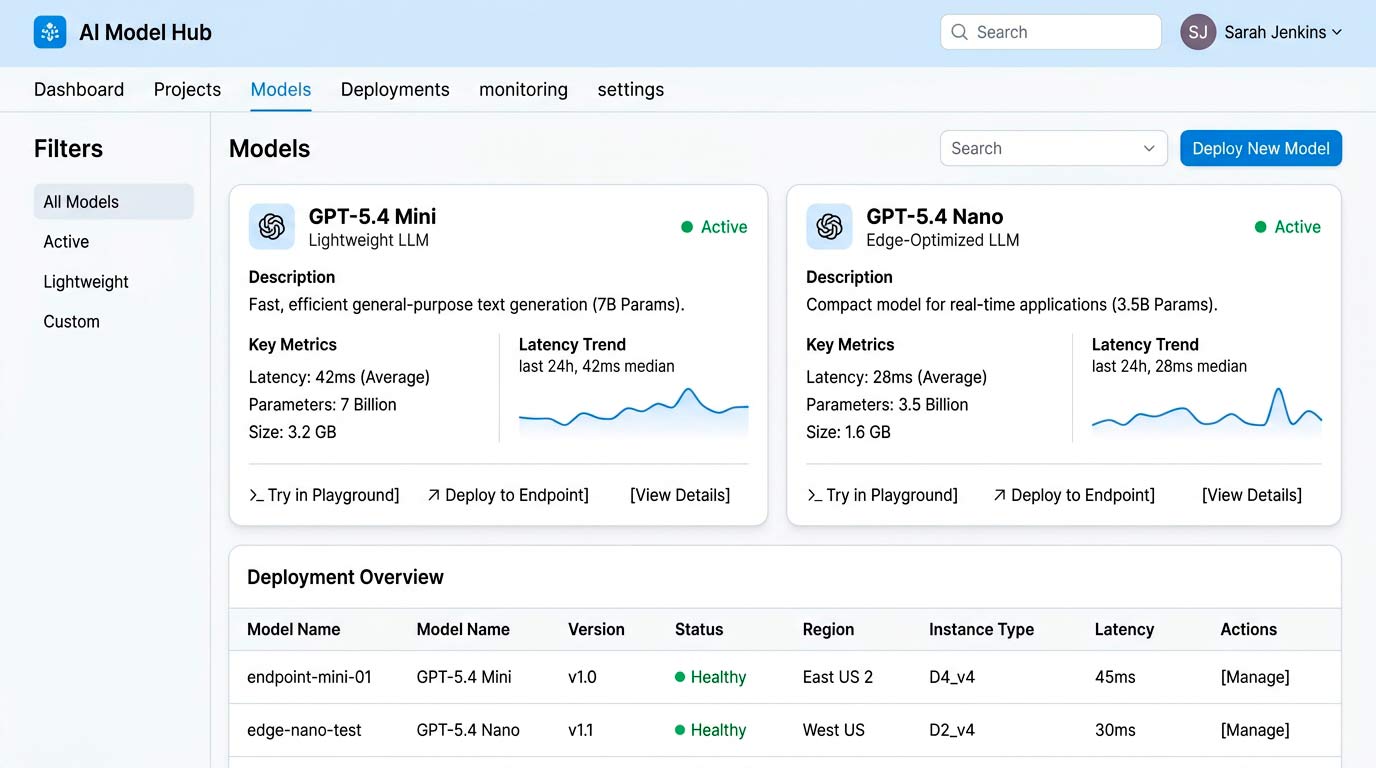
OpenAI announced GPT-5.4 Mini and GPT-5.4 Nano as part of its GPT-5.4 model family, positioning them as more efficient alternatives to larger models. According to the company, the models are intended to support faster response times and lower compute requirements.
Microsoft also confirmed that both models are available through Azure AI Foundry, where they are integrated into its developer and enterprise AI platform.
Key changes in the new lightweight models
- Introduction of two lightweight models
- Positioning around lower-latency inference and reduced resource usage
- Availability through Azure AI Foundry for enterprise deployment
- Further expansion of OpenAI’s model tiering strategy
OpenAI describes the new models as suitable for applications where speed and efficiency are prioritized over maximum capability.
Technical details of the lightweight models
Details about internal architecture or benchmark results were not disclosed in the provided sources. Based on the release material, the models are positioned as lighter-weight options within the broader GPT-5.4 family.
According to Microsoft, the models are intended for scenarios such as:
- Real-time applications requiring low latency
- High-throughput workloads
- Cost-sensitive deployments
The Azure AI Foundry rollout also suggests closer integration with Microsoft’s existing enterprise AI tooling.
Why the new models matter
The release shows how OpenAI is segmenting its model lineup for different deployment needs rather than treating every use case the same. For developers, smaller models may be useful in applications where response speed and operating cost matter more than access to a larger model tier.
For enterprises already using Azure AI Foundry, the availability of these models may make it easier to evaluate lighter-weight options inside existing cloud workflows.
Industry reaction to the release
Early Reddit discussion suggests mixed community sentiment. Some users viewed the models as practical for targeted use cases, while others questioned the trade-off between efficiency and capability compared with larger models.
That response reflects a familiar tension in AI product releases: lower latency and lower cost can be attractive, but developers still want clarity on capability limits.



